Escribo este artículo precisamente para aclarar una serie de preguntas de las que he sido objeto en días en que se ha desatado la mayor guerra cibernética de la historia. Es estos últimos día debido al caso WikiLeaks, hemos escuchado y leido acerca del término
DDoS en repetidas ocasiones, asociado a varios ataques realizados a sitios importantes de uno y de otro bando de la confrontación y es necesario aclarar qué significa.
Para empezar hablemos de
DoS, aunque parezcan las siglas de un viejo y recordado sistema operativo hay que notar que la "o" del medio en este acrónimo está en minúsculas intencionalmente, precisamente porque era una manera de diferenciar a este tipo de ataque conocido como
Denial of Service (Negación de Servicio) del viejo sistema operativo DOS.
La técnica de
DoS en palabras simples se basa en solicitar un recurso a un servidor web desde varias locaciones simultáneamente y una gran cantidad de veces de forma que el servidor no pueda atender a otras solicitudes.
Tomemos el clásico el ejemplo del cantinero que puede atender a una serie de clientes en una barra de un bar y de repente se ve completamente agobiado ante las solicitudes de dos equipos completos de fútbol que han llegado a festejar a bar, dejando mal atendidos o desatendidos a los clientes habituales.
En los casos del DoS tradicional la idea es solicitar un recurso muy "pesado" en cuanto a tamaño y potencia de CPU mediante un simple URL que no tiene prácticamente costo de ancho de banda. Sin embargo esta técnica ya no es efectiva ya que cualquier firewall o cortafuegos puede controlar la cantidad de ancho de banda utilizado en satisfacer a un solo cliente y si esta es excesiva bloquea automáticamente las solicitudes provenientes de dicho cliente.
La técnica fue perfeccionándose y los ataque se basaron ya no en solicitar recursos complejos, sino en ubicar una deficiencia en la programación que indujera a errores no controlados (Exploits) para reproducirla la cantidad de veces necesaria para que el servidor quede sin recursos de memoria, espacio en disco u otro recurso necesario. Sin embargo al corregir la vulnerabilidad el método quedaba obsoleto y solo era efectivo en servidores que no hubieran corregido el problema, lo que reducía la efectividad con el tiempo.
A veces la aplicación de la técnica podía ser tan sencilla como ejecutar un error en código tal cantidad de veces que el archivo de registro de sucesos de errores crecía tanto que ocupaba todo el espacio disponible en el equipo del servidor.
Pero esos eran tiempos pasados, el problema ahora es otro aunque los métodos se basan en el mismo principio. Cuando hablamos de
DDoS (con una D más) nos referimos a
Distributed Denial of Service.
Para hablar de esta vertiente mucho más compleja del DoS original es necesario explicar que es una
BotNet. El término proveniente de "Ro
bots Net" o red de robots y se usa para denominar a una red de computadores que han sido infectados con un troyano (o rootkit) que permite al hacker utilizarlos como zombies para enviar SPAM, generar ataques de fuerza bruta para obtención de credenciales y otras técnicas del lado oscuro, como por ejemplo el
DDos. Las BotNets usualmente "pertenecen" a un Hacker o grupo de hackers específico. Mientras más grande la BotNet más "poderoso" es el hacker.
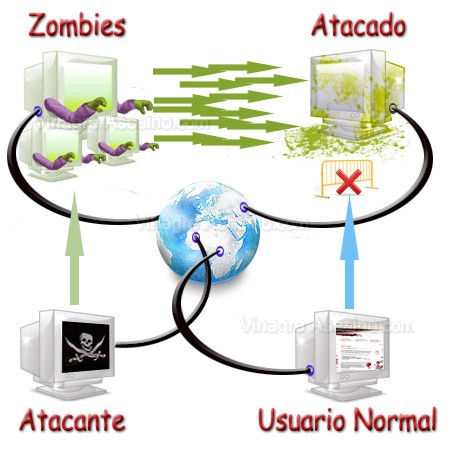
Efectivamente en suma el
DDoS no es más que un ataque de negación de servicio pero distribuido, ejecutado a través de una red de computadores zombies. Sin embargo es muy difícil de detener, ya que no se puede diferenciar el origen del ataque para bloquear las solicitudes ya que estas difícilmente se pueden aislar de las de los clientes reales. Además el hacker utiliza a sus zombies como batallones que atacan en grupos y a diferente flancos (diferentes recursos).
Todos estos zombies en la mayoría de los casos son controlados mediante instrucciones colocadas en un canal de IRC (Internet Relay Chat), una de las más antiguas formas de chatear en la red. Ellos simplemente se conectan a un puerto determinado en un servidor con un dominio flotante, obteniendo instrucciones cada tantos minutos y ejecutándolas.
Aunque estoy a favor de la libertad de expresión y especialmente en el ciberespacio, creo que lo que debiera preocuparnos algo más la cantidad de equipos infectados que están interviniendo en esta guerra virtual. Usted pudiera estar interviniendo en ella mientras lee este artículo sin saberlo.
Hasta la próxima...